谷歌加倍投入人工智能:Veo 3、Imagen 4 和 Gemini Diffusion 拓展創意邊界

谷歌 I/O 2025 大會從來都不是那種精打細算的大會。 今年,該公司放棄了漸進式的策略,推出了一系列生成式 AI 升級,旨在重塑搜索、視頻和數字創意的格局。
關鍵在於:谷歌的下一代模型系列 Gemini,現在為從搜索結果到視頻合成和高分辨率圖像創建等一切事物提供支持——在日益由人工智能生成速度和原生程度決定的競賽中開闢了新的領域。
最精彩的是Veo 3谷歌首款 AI 視頻生成器,不僅能生成視覺效果,還能生成完整的音軌——環境噪音、特效,甚至對話——並與素材直接同步。 輸入文字和圖片提示,即可生成完整的 4K 視頻。
這是第一個能夠同時生成音頻和視覺效果的大規模視頻模型——這一趨勢始於節目主持人阿爾法,一款未發布的型號,但 Veo3 提供了更多的功能,可以生成超越簡單 2D 卡通動畫的各種風格。
谷歌實驗室副總裁喬希·伍德沃德 (Josh Woodward) 在發布會上表示:“我們正在進入一個融合音頻和視頻生成的全新創作時代。” 這對目前視頻生成領域的領導者——Kling、Hunyuan、Luma、Wan 以及 OpenAI 的 sora——構成了直接挑戰,這些公司將 Veo 定位為一體化解決方案,而非需要多種工具。
除了 Veo3 之外,Imagen 4(谷歌圖像生成器模型的最新版本)還具有增強的照片真實感、2K 分辨率,或許最重要的是,它還具有適用於標牌、產品和數字模型的文本渲染功能。
對於那些曾經遭受過之前的 AI 圖像模型所創建的亂碼文本的人來說,Imagen 4 代表著一個重大的改進。
這些工具並非孤立存在。 FLOW AI 是一項面向專業用戶的全新訂閱功能,它將 Veo、Imagen 和 Gemini 的語言功能整合到一個統一的電影製作和場景編輯環境中。 但這種整合需要付費——在促銷期內,每月需支付 125 美元才能使用完整的工具包,直至 250 美元的全價開始收費。

Gemini:助力搜索和“文本傳播”
生成式人工智能並非只適用於內容創作者。 Gemini 2.5 現已成為該公司重新設計的搜索引擎的支柱,谷歌希望將其從鏈接聚合器發展成為一個動態的對話界面,能夠處理複雜的查詢並提供綜合的多源答案。
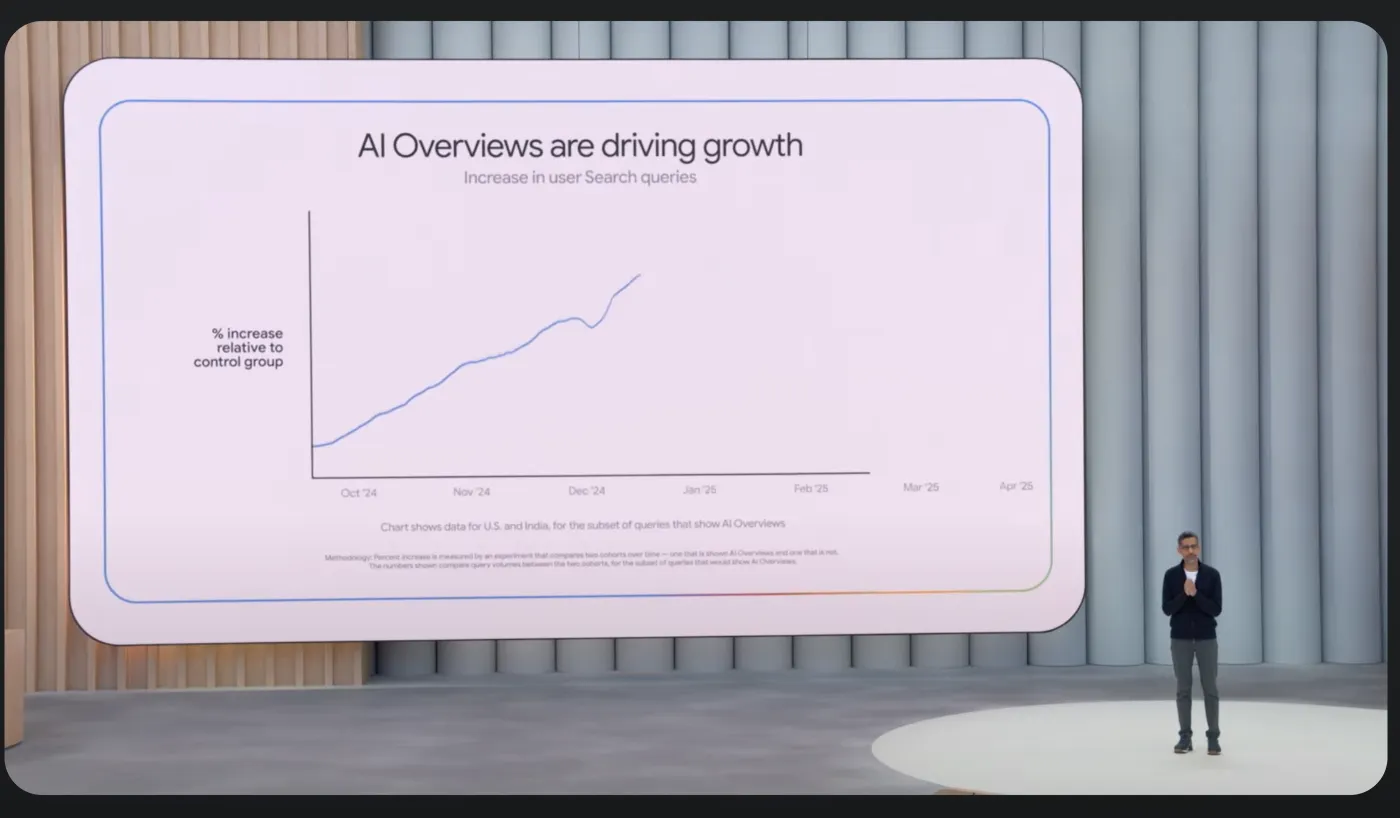
AI 概覽(Google Gemini 嘗試為查詢提供全面的答案,而無需用戶點擊其他網站)現在位於搜索頁面的頂部,據 Google 報告,每月用戶超過 15 億。
另一個有趣的開發項目是“Gemini Diffusion”,它採用了由初始實驗室幾個月前。 直到最近,人工智能界普遍認為自回歸技術最適合文本生成,而擴散技術則更適合圖像生成。
自回歸模型在讀取所有先前的代數之後生成每個新標記,以確定最佳的下一個標記——非常適合通過不斷審查提示和先前的輸出來製作連貫的文本響應。
擴散技術的運作方式不同,它首先用隨機信息填充所有上下文,然後每一步細化(擴散)輸出,使最終產品與提示相匹配——非常適合具有固定畫布和美感的圖像。
OpenAI 首次成功將自回歸生成應用於圖像模型,而如今,谷歌已成為首家將擴散生成應用於文本的大型公司。 這意味著該模型從無意義的內容開始,並在每次迭代中完善整個輸出,每秒生成數千個標記,同時保持準確性——例如,Groq(不是 xAI 的 GROK)是世界上最快的推理提供商之一,每秒生成近 275 個標記,而 OpenAI 或 Anthropic 等傳統提供商的速度都無法接近這一速度。
然而,該模型尚未公開發布——感興趣的用戶必須加入候補名單—但早期採用者分享了令人印象深刻的結果,展示了該模型的速度和精度。
親身體驗 Google 的 AI 工具
我們嘗試了 Google 的幾項新 AI 功能,根據層級不同,結果也有所不同。
深度研究功能極其強大,甚至超越了 ChatGPT 的替代方案。 這款綜合研究代理評估了數百個來源,並以極低的錯誤率提供可靠的信息。
它比 OpENAI 的研究代理更具優勢,因為它能夠生成信息圖表。 在生成完整的研究文本後,它可以將這些信息濃縮成視覺上引人入勝的幻燈片。 我們向模型輸入了有關谷歌最新公告的所有內容,它通過圖表、方案、圖形和思維導圖等方式呈現了準確的信息。
Veo 3 仍為 Gemini 極端主義者 用戶專屬,不過一些第三方提供商(例如 Freepik 和 Fal.ai)已提供 API 訪問權限。 除非您購買 Ultra 套餐,否則無法試用 Flow。
FloW 是一款直觀的視頻編輯器,以 Veo 的模型為核心,用戶可以使用簡單的文本提示來編輯、剪切、擴展和修改 AI 場景。
然而,即使是 Veo2 也得到了一些關注,這讓專業版用戶的工作更加輕鬆。 如今 Veo2 的運行速度顯著提升——我們用大約 30 秒的時間製作了 8 秒的視頻。 雖然 Veo2 缺乏聲音,目前僅支持文本轉視頻(圖片轉視頻功能即將推出),但它能夠理解我們的提示,甚至生成連貫的文本。
Veo2 的性能已與 Kling 2.0 相媲美——後者被廣泛認為是生成視頻行業的質量標杆。 搭載 Veo3 的新一代產品看起來更加逼真、連貫,背景音效出色,對話和聲音也栩栩如生。
對於 Imagen,乍一看很難判斷 Google 在其 Gemini 聊天機器人界面上是採用了版本 4 還是仍在使用版本 3,不過用戶可以通過 Whisk 進行確認。 我們的初步測試表明,除非另有說明,Imagen 4 更注重真實感,其即時響應速度更快,視覺效果也超越了其前代產品。
我們生成了一張包含不同元素的圖像,這些元素通常不會在同一場景中組合在一起。 我們的主題是“照片中,一位皮膚由玻璃製成的女性,周圍環繞著成千上萬的閃閃發光的飄渺碎片,身處一間巴洛克風格的房間,霓虹燈上寫著‘解密’,非常逼真。”
儘管 Imagen 3 和 Imagen 4 都理解了概念和要素,但 Imagen 3 未能捕捉到逼真的風格——而 Imagen 4 卻輕鬆做到了。 總體而言,Imagen 4 與 SOTA 圖像生成器相當,尤其是考慮到它易於提示。
音頻概覽也得到了改進,現在模型可以輕鬆地在 Gemini 上提供超過 20 分鐘的完整辯論,而無需用戶切換到 筆記本LM。 這使得 Gemini 擁有更完善的界面,減少了用戶之前在不同網站之間跳轉獲取各種服務的碎片化現象。
質量可與NotebookLM,平均輸出略長。 然而,關鍵特性並非在於模型本身更優秀,而是它現在已嵌入到 Gemini 的聊天機器人 UI 中。
高價位的優質人工智能
谷歌並沒有隱藏其盈利策略。 該公司的“Ultra該計劃每月收費 250 美元,包含優先使用最強大的模型、Flow AI 工具和 30TB 的存儲空間——目標客戶顯然是電影製作人、嚴肅的創作者和企業。20 美元的“AI Pro”套餐可解鎖谷歌之前的 Veo2 模型,以及面向更廣泛用戶群的圖像和生產力功能。基礎生成工具(例如簡單的 Gemini Live 和圖像創建)仍然免費,但受到代幣上限和每月僅 10 次研究等限制。
這種分層方法反映了更廣泛的人工智能市場趨勢:用免費產品推動大規模採用,然後用實用功能牢牢抓住專業人士。 谷歌押注的是,真正的行動(和利潤)在於高端創意工作和自動化企業工作流程,而不僅僅是隨意的提示和模因生成.
編輯安德魯·海沃德
