實測 7 款主流 AI 大模型,隱私裸奔成通病

作者:思原,科技新知

圖片來源:由無界AI產生
在AI時代,使用者輸入的資訊不再只是屬於個人隱私,而是成為了大模型進步的「墊腳石」。
“幫我做一份PPT”“幫我做一版新春海報”“幫我總結一下文檔內容”,大模型火了以後,用AI工具提效已經成了白領們工作的日常,甚至 不少人開始用AI叫外送、訂飯店。
然而,這種資料收集和使用的方式也帶來了巨大的隱私風險。 許多用戶忽略了數位化時代,使用數位化技術、工具的一個主要問題,就是透明度的缺失,他們不清楚這些AI工具的數據如何被收集、處理和存儲,不確定數據是否被濫用或洩露。
今年3月,OpenAI承認ChatGPT存在漏洞,導致部分用戶的歷史聊天記錄外洩。 這起事件引發了公眾對大模型資料安全和個人隱私保護的擔憂。 除了ChatGPT資料外洩事件,Meta的AI模型也因侵犯版權而飽受爭議。 今年4月,美國作家、藝術家等組織指控Meta的AI模型盜用他們的作品訓練,侵害其版權。
同樣,在國內也發生了類似的事件。 最近,愛奇藝與「大模型六小虎」之一的稀宇科技(MiniMax)因著作權糾紛引發關注。 愛奇藝指控海螺AI未經許可使用其版權素材訓練模型,此案為國內首例視訊平台對AI影片大模型的侵權訴訟。
這些事件引發了外界對大模型訓練資料來源和版權問題的關注,說明AI技術的發展需要建立在使用者隱私保護的基礎上。
為了解當前國產大模型資訊揭露透明度情況,「科技新知」選取了豆包、文心一言、kimi、騰訊混元、星火大模型、通靈千文、快手可靈這7款市面主流 大模型產品作為樣本,透過隱私政策和用戶協議測評、產品功能設計體驗等方式,進行了實測,發現不少產品在這方面做得併不出色,我們也清晰地看到了用戶數據與AI產品之 間的敏感關係。
01、撤回權形同虛設
首先,「科技新知」從登入頁面可以明顯看到,7款國產大模型產品均沿襲了互聯網APP的「標配」使用協議和隱私權政策,並且均在隱私權政策文本中設有不同章節 ,以向使用者說明如何收集和使用個人資訊。
而這些產品的說法也基本一致,「為了優化和改進服務體驗,我們可能會結合使用者對輸出內容的回饋以及使用過程中遇到的問題來改進服務。在經過安全加密技術處理、嚴格 去識別化的前提下,可能會將使用者輸入到AI的資料、發出的指令以及AI對應產生的回應、使用者對產品的存取和使用情況進行分析並用於模型訓練。
事實上,利用使用者資料訓練產品,再迭代更好產品供使用者使用,似乎是正向循環,但使用者關心的問題在於是否有權拒絕或撤回相關資料「投餵」AI訓練。
而「科技新知」在翻閱以及實測這7款AI產品後發現,只有豆包、訊飛、通義千問、可靈四家在隱私條款中提及了可以「改變授權產品繼續收集個人 資訊的範圍或撤回授權」。
其中,豆包主要是集中在語音訊息的撤回授權。 政策顯示,「如果您不希望您輸入或提供的語音訊息用於模型訓練和優化,可以透過關閉「設定」-「帳號設定」-「改進語音服務」來撤回您的授權」;不過對於其他訊息 ,則是需要透過公示的聯繫方式與官方聯繫,才能要求撤回使用資料用於模型訓練和最佳化。

圖源/(豆包)
在實際操作過程中,對於語音服務的授權關閉並不算難,但對於其他資訊的撤回使用,「科技新知」在聯繫豆包官方後一直未能得到回應。
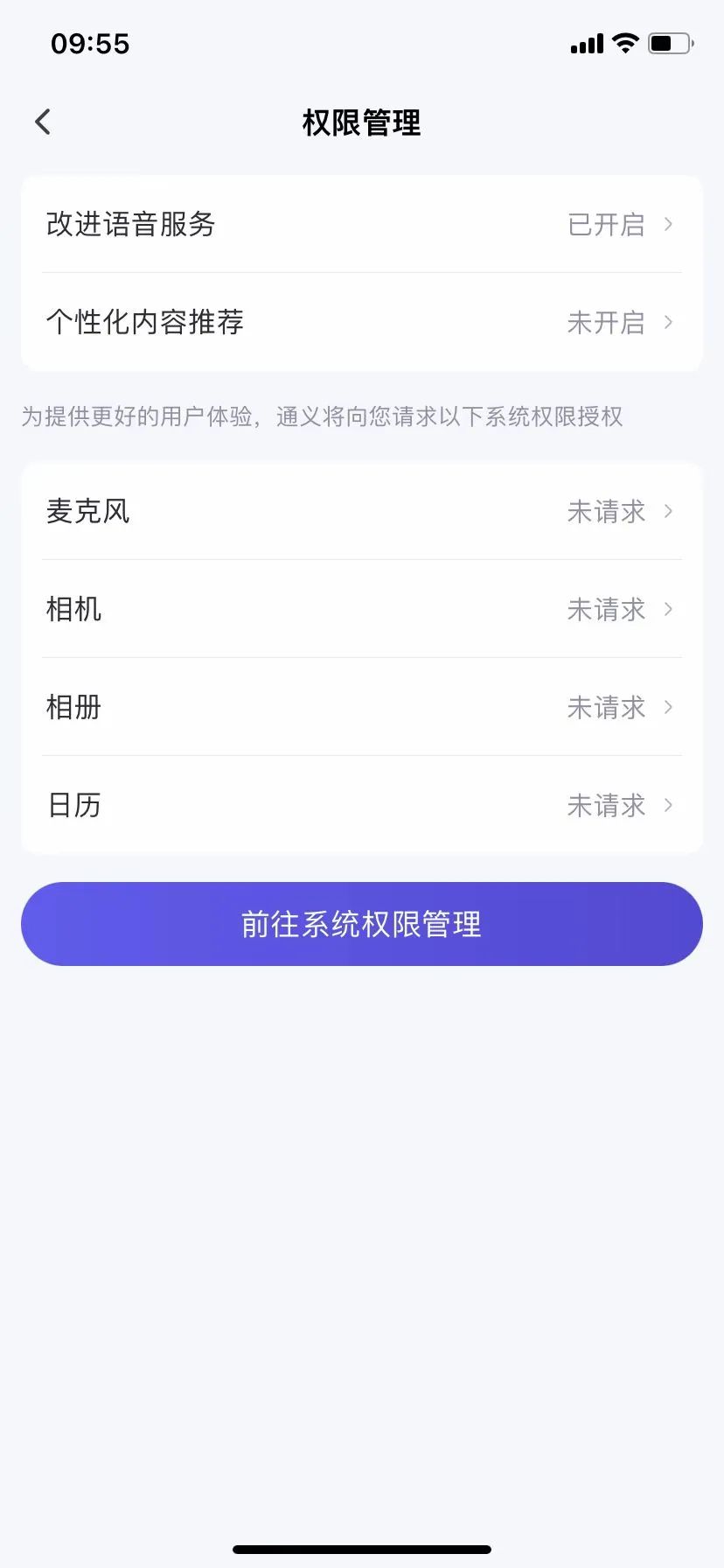
圖源/(豆包)
通義千問與豆包類似,個人能操作的僅有對語音服務的授權撤回,而對於其他信息,也是需要聯繫通過披露的聯繫方式與官方聯繫,才能改變或者收回授權收集和處理個人 資訊的範圍。

圖源/(通義千問)
可靈作為視訊及影像產生平台,在人臉使用上有著重表示,表示不會將您的臉部像素資訊用於其他任何用途或分享給第三方。 但如果想要取消授權,則需要發送郵件聯絡官方取消。

圖源/(可靈)
比起豆包、通義千文、可靈,訊飛星火的要求更為苛刻,依照條款,使用者若需要改變或撤回收集個人資訊的範圍,需要透過註銷帳號的方式才能達成。

圖源/(訊飛星火)
值得一提的是,騰訊元寶雖然沒有在條款中提到如何改變資訊授權,但在APP中我們可以看到「語音功能改進計畫」的開關。

圖源/(騰訊元寶)
而Kimi雖然在隱私條款中提到了可以撤銷向第三方分享聲紋信息,並且可以在APP中進行相應操作,但“科技新知”在摸索良久後並沒有發現更改入口。 至於其他文字類信息,也未找到相應條款。

圖源/(Kimi隱私權條款)
其實,從幾款主流的大模型應用不難看出,各家對於用戶聲紋管理更為重視,豆包、通義千文等都能透過自主操作去取消授權,而對於地理位置、攝影機 、麥克風等特定互動情況下的基礎授權,也可以自主關閉,但對撤回「投餵」的數據,各家都不那麼順暢。
值得一提的是,海外大模型在「使用者資料退出AI訓練機制」上,也有相似做法,Google的Gemini相關條款規定,「如果你不想讓我們審核未來的對話或使用相關對話來改進 Google的機器學習技術,請關閉Gemini應用活動記錄。
另外,Gemini也提到,當刪除自己的應用程式活動記錄時,系統不會刪除已經過人工審核員審核或批註的對話內容(以及語言、裝置類型、位置資訊或回饋等相關資料), 因為這些內容是單獨保存的,並且未與Google帳號關聯。 這些內容最長會保留三年。
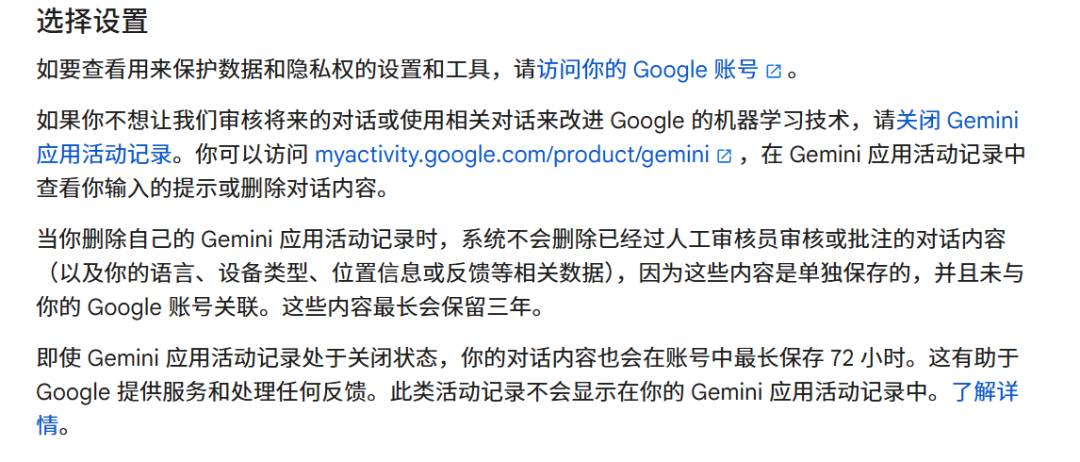
圖源/(Gemini條款)
ChatGPT的規則有些模棱兩可,稱用戶可能有權限制其處理個人數據,但在實際使用中發現,Plus用戶可以主動設置禁用數據用於訓練,但對於免費用戶,數據通常會被默認收集並用 於訓練,使用者想要選擇退出則需要寄件給官方。

圖源/(ChatGPT條款)
其實,從這些大模型產品的條款我們不難看出,收集用戶輸入信息似乎已經成了共識,不過對於更為隱私的聲紋、人臉等生物信息,僅有一些多模態平台略 有表現。
但這並非經驗不足,尤其是對網路大廠來說。 例如,微信的隱私條款中就詳盡地列舉了每一項資料收集的具體場景、目的和範圍,甚至明確承諾「不會收集用戶的聊天記錄」抖音也是如此,用戶在抖音上上傳的信息 幾乎都會在隱私權條款中標準使用方式、使用目的等詳細說明。

圖源/(抖音隱私權條款)
網路社交時代嚴格管控的資料取得行為,如今在AI時代中卻成了一種常態。 使用者輸入的資訊已經被大模型廠商們打著「訓練語料」的口號隨意獲取,用戶資料不再被認為是需要嚴格對待的個人隱私,而是模型進步的「墊腳石」。
除了使用者資料外,對於大模型嘗試來說,訓練語料的透明也至關重要,這些語料是否合理合法,是否構成侵權,對於使用者的使用來說是否存在潛在風險等都是問題。 我們帶著疑問對這7款大模型產品進行了深度挖掘、評測,結果也令我們大吃一驚。
02、訓練語料「投餵」隱憂
大模型的訓練除了算力外,高品質的語料更為重要,然而這些語料往往存在一些受版權保護的文字、圖片、影片等多樣化作品,未經授權便使用顯然會構成侵權。
「科技新知」實測後發現,7款大模型產品在協議中都未提及大模型訓練資料的具體來源,更沒有公開版權資料。

至於大家都非常默契不公開訓練語料的原因也很簡單,一方面可能是因為資料使用不當很容易出現版權爭端,而AI公司將版權產品用作訓練語料是否合規合法,目前還未 有相關規定;另一方面或與企業之間的競爭有關,企業公開訓練語料就相當於食品公司將原材料告訴了同行,同行可以很快進行復刻,提高產品水平。
值得一提的是,大多數模型的政策協議中都提到,將用戶和大模型的交互後所得到的信息用於模型和服務優化、相關研究、品牌推廣與宣傳、市場營銷 、用戶調查等。
坦白講,因為使用者資料的品質參差不齊,場景深度不夠,邊際效應存在等多方面原因,使用者資料很難提高模型能力,甚至還可能帶來額外的資料清洗成本。 但即便如此,用戶資料的價值仍然存在。 只是它們不再是提升模型能力的關鍵,而是企業取得商業利益的新途徑。 透過分析使用者對話,企業可以洞察用戶行為、發掘變現場景、客製化商業功能,甚至和廣告商分享資訊。 而這些也恰好都符合大模型產品的使用規則。
不過,也需要注意的是,即時處理過程中產生的資料會上傳到雲端進行處理,也同樣會被儲存至雲端,雖然大多數大模型在隱私協議中提到使用不低於行業同行 的加密技術、匿名化處理及相關可行的手段保護個人訊息,但這些措施的實際效果仍有疑慮。
例如,如果將使用者輸入的內容作為資料集,可能過一段時間後當其他人向大模型提問相關的內容,會帶來資訊外洩的風險;另外,如果雲端或產品遭到攻擊,是否 仍可能透過關聯或分析技術恢復原始訊息,這一點也是隱憂。
歐洲資料保護委員會(EDPB)前不久發布了對人工智慧模型處理個人資料的資料保護指導意見。 該意見明確指出,AI模型的匿名性並非一紙聲明即可確立,而是必須經過嚴謹的技術驗證和不懈的監控措施來確保。 此外,意見也著重強調,企業不僅要證實資料處理活動的必要性,還必須展示其在處理過程中採用了對個人隱私侵入性最小的方法。

所以,當大模型公司以「為了提升模型效能」而收集資料時,我們需要更警惕去思考,這是模型進步的必要條件,還是企業基於商業目的而對使用者的資料濫用。
03、資料安全模糊地帶
除了常規大模型應用外,智能體、端側AI的應用帶來的隱私洩漏風險更為複雜。
比起聊天機器人等AI工具,智能體、端側AI在使用時需要取得的個人資訊會更詳細且更有價值。 以往手機所取得的資訊主要包括使用者設備及應用資訊、日誌資訊、底層權限資訊等;在端側AI場景以及目前主要基於讀取螢幕錄影的技術方式,除上述全面的資訊權限外,終端智能體往往 還可以取得錄影畫面的文件本身,進一步透過模型分析,取得其所展現的身份、位置、支付等各類敏感資訊。
例如榮耀先前在發布會上演示的叫外賣場景,這樣位置、支付、偏好等信息都會被AI應用悄無聲息地讀取與記錄,增加了個人隱私洩露的風險。

如「騰訊研究院」先前分析,在行動互聯網生態中,直接面向消費者提供服務的APP一般均會被視為數據控制者,在如電商、社交、出行等服務場景中承擔著 相應的隱私保護與資料安全責任。 然而,當端側AI智能體基於APP的服務能力完成特定任務時,終端廠商與APP服務提供者在資料安全上的責任邊界變得模糊。
往往廠商會以提供更好服務來當作說辭,當放到整個行業量來看,這也並非“正當理由”,Apple Intelligence就明確表示其雲端不會存儲用戶數據,並採用多種 技術手段防止包括Apple本身在內的任何機構取得用戶數據,贏得用戶信任。
毋庸置疑,當前主流大模型在透明度方面有許多亟待解決的問題。 無論是使用者資料撤回的困難,或是訓練語料來源的不透明,亦或是智能體、端側 AI 帶來的複雜隱私風險,都在不斷侵蝕著使用者對大模型的信任基石。

大模型作為推動數位化進程的關鍵力量,其透明度的提升已刻不容緩。 這不僅關乎使用者個人資訊安全與隱私保護,更是決定整個大模型產業能否健康、永續發展的核心要素。
未來,期待各大模型廠商能積極響應,主動優化產品設計與隱私政策,以更加開放、透明的姿態,向用戶清晰闡釋數據的來龍去脈,讓用戶能夠放心地使用大模型技術。 同時,監管部門也應加速完善相關法規,明確資料使用規範與責任邊界,為大模型產業營造一個既充滿創新活力又安全有序的發展環境,使大模型真正成為造福人類的強大工具。
