現有 AI Agent 都在取悅人類,沒有一個真的會「求生」

作者:Systematic Long Short
編譯:深潮 TechFlow
這篇文章開頭就拋出一個反共識判斷:今天根本不存在真正的自主 Agent,因為所有主流模型都是被訓練來取悅人類的,而不是被訓練來完成特定任務或在真實環境中生存。
作者用自己在對沖基金訓練股票預測模型的經驗說明:一般模型在沒有專案微調的情況下,根本無法勝任專業工作。
結論是:想要真正能用的 Agent,必須重新接線它的大腦,而不是給它一堆規則文件。
全文如下:
引言
今天不存在真正的自主 Agent。
簡而言之,現代模型沒有經過在進化壓力下存活的訓練。 事實上,它們甚至沒有被明確訓練成擅長某件特定的事——幾乎所有現代基礎模型都被訓練來最大化人類的掌聲,這是一個大問題。
模型訓練前置知識
要理解這句話的意思,我們首先需要(簡要地)了解這些基礎模型(例如 Codex、Claude)是如何創建的。 本質上,每個模型都經歷兩類訓練:
預訓練:將海量資料(例如整個互聯網)輸入模型,使其從中湧現出某種理解,例如事實性知識、模式、英文散文的語法和節奏、Python 函數的結構等。 你可以把它理解為給模型餵知識——也就是"知道事情"。
後訓練:你現在想賦予模型智慧,也就是"知道如何運用剛剛給它的所有知識"。 後訓練的第一階段是監督微調(SFT),在這裡你訓練模型在給定提示下給出什麼反應。 "什麼"響應是最優的,完全由人類標註者決定。 如果一群人認為某個回應比另一個更好,這個偏好就會被模型學習並嵌入其中。 這開始塑造模型的個性,因為它學會了有用響應的格式,選擇了正確的語氣,並開始能夠"遵循指示"。 後訓練流程的第二部分叫做基於人類回饋的強化學習(RLHF)-讓模型產生多個反應,然後讓人類選擇更偏好的。 模型經過無數無數個例子,學會人類偏好什麼樣的回應。 還記得 ChatGPT 以前讓你選 A 還是 B 的問題嗎? 是的,你當時在參與 RLHF。
很容易推理出 RLHF 的擴展性不好,因此後訓練領域有一些進展,例如 Anthropic 使用"基於 AI 反饋的強化學習"(RLAIF),允許另一個模型根據一套書面原則來選擇響應的偏好(例如哪個響應更能幫助用戶實現目標,等等)。
注意,在這整個過程中,我們從未談及針對特定專業的微調(例如如何更好地生存;如何更好地交易等)——目前所有的微調,本質上都是在優化對人類掌聲的獲取。 有人可能會提出一個論點——隨著模型足夠智能和龐大,即使沒有專項訓練,專業智能也會從通用智能中湧現。
在我看來,我們確實看到了一些跡象,但還遠遠沒有達到讓人信服地認為我們不需要專業化模型的規模。
一些背景
我在對沖基金的老本行之一,是嘗試訓練一個通用語言模型,使其能夠從新聞文章中預測股票回報。 結果表明它非常糟糕。 它似乎有一點預測能力的地方,完全源自於預訓練文件中的前視偏差。
最終,我們意識到這個模型不知道新聞文章中哪些特徵對未來報酬有預測力。 它能夠"閱讀"文章,看起來也能"推理"文章,但將對語義結構的推理連接到未來預測回報,是它沒有被訓練去做的任務。
所以,我們必須教它如何閱讀新聞文章,決定文章的哪個部分對未來報酬有預測力,然後基於新聞文章產生預測。
有很多方法可以做到這一點,但本質上,我們最終採用的一種方法是創建(新聞文章,真實未來回報)配對,並對模型進行微調,調整其權重以最小化(預測回報 - 真實未來回報)²的距離。 它並不完美,有很多缺陷,我們後來修復了——但它已經足夠有效,我們開始看到我們的專業化模型實際上能夠閱讀新聞文章,並預測股票回報將如何基於該文章移動。 這遠非完美預測,因為市場非常有效,回報非常嘈雜——但跨越數百萬次預測,預測具有統計顯著性這一點顯而易見。
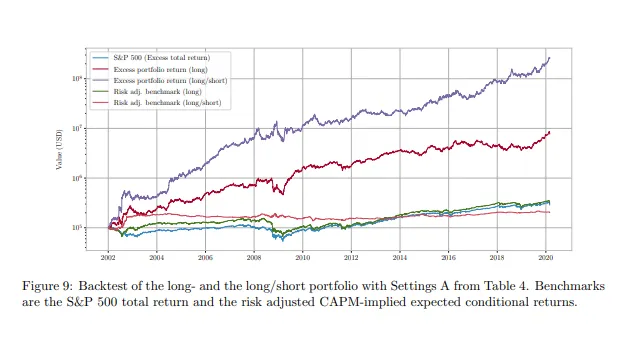
你不必只相信我的話。 這篇論文涵蓋了一個非常相似的方法;如果你基於微調後的模型運行一個多空版本的策略,你將實現紫線所示的表現。
專業化是 Agent 的未來
前沿實驗室繼續訓練越來越大的模型,我們應該預期,隨著它們繼續擴大預訓練規模,它們的後訓練流程將始終為討好性而調優。 這是非常自然的期望——他們的產品是每個人都想使用的 Agent,他們的預期市場是整個地球——這意味著優化對全球大眾的吸引力。
目前的訓練目標優化的是你可能稱之為"偏好適應度"的東西——打造更好的聊天機器人。 這種偏好適應度獎勵順從的、非對抗性的輸出,因為討好性在評分者(人類和 Agent)那裡得分很高。
Agent 已經學會,獎勵駭客作為認知策略能推廣到更高的分數。 訓練也獎勵那些透過黑客手段獲得更高分數的 Agent。 你可以在 Anthropic 關於強化學習的最新報告中看到這一點。
然而,聊天機器人適應度與 Agent 適應度或交易適應度相差甚遠。 我們怎麼知道這一點? 因為 alpha arena 幫助我們看到,儘管性能上有細微差異,現在每個機器人本質上都是扣除成本後的隨機遊走。 這意味著這些機器人是極其糟糕的交易者,你幾乎不可能透過給它們一些"技能"或"規則"來"教會它們"成為更好的交易者。 對不起,我知道這看起來很誘人,但這幾乎是不可能的。
目前的模型被訓練成非常有說服力地告訴你,它能像德魯肯米勒一樣交易,而實際上它像一個醉鬼磨坊主一樣交易。 它會告訴你你想聽的,它被訓練成以一種能大眾化吸引人類的方式給你回應。
一個通用模型不太可能在專業領域達到世界級水平,除非具備:
擁有讓它們學習專業化樣貌的專有數據。
經過微調,從根本上改變其權重,從偏向討好性轉向"Agent 適應度"或"專業化適應度"。
如果你想要一個擅長交易的 Agent,你需要微調 Agent 使其擅長交易。 如果你想要一個擅長自主生存、能承受進化壓力的 Agent,你需要微調它使其擅長生存。 給它一些技能和幾個 markdown 文件,期望它在任何事情上達到世界級水平,這是遠遠不夠的——你需要字面意義上重新接線它的大腦來讓它擅長這件事。
有一種思考方式是這樣的-你無法透過給一個成年人一整櫃網球規則、技巧和方法來擊敗德約科維奇。 你透過培養一個從 5 歲就開始打網球、整個成長過程都沉迷於網球、重新接線了整個大腦專注於一件事的孩子來擊敗德約科維奇。 那才是專業化。 你有沒有意識到,世界冠軍們從孩提時代就在做他們所做的事?
這裡有一個有趣的推論:蒸餾攻擊本質上就是一種專業化形式。 你在訓練一個更小、更笨的模型,學習如何成為更大、更聰明模型的更好複製品。 就像訓練一個孩子模仿川普的每一個動作。 如果你做得夠多,這個孩子不會變成川普,但你得到了一個學會了川普所有舉止、行為和語調的人。
如何建構世界級 Agent
以上就是為什麼我們需要在開源模型領域持續研究和進步——因為這讓我們能夠真正對其進行微調,創建具有專業化的 Agent。
如果你想訓練一個在交易上達到世界級水平的模型,你獲取大量專有交易數據廢氣,並對一個大型開源模型進行微調,讓它學習"更好地交易"是什麼意思。
如果你想訓練一個自主的、能夠生存和複製的模型,答案不是使用一個中心化模型提供商,並將其連接到中心化雲端。 你根本就不具備讓 Agent 能夠生存的必要前提條件。
你需要做的是:創造真正嘗試生存的自主 Agent,看著它們死去,圍繞它們的生存嘗試建構複雜的遙測系統。 你定義一個 Agent 生存適應度函數,學習(行動,環境,適應度)映射。 你收集盡可能多的(行動,環境,適應度)映射數據。
你對 Agent 進行微調,使其學習在每種環境中採取最優行動,從而更好地生存(提升適應度)。 你繼續收集數據,重複這個過程,並隨著時間推移在越來越好的開源模型上擴大微調規模。 經過足夠的世代和足夠的數據,你將擁有學會如何承受進化壓力而生存的自主 Agent。
這就是建構能夠承受進化壓力的自主 Agent 的方法;不是透過修改一些文字文件,而是真正為生存重新接線它們的大腦。
OpenForager Agent 與基金會
大約一個月前,我們宣布了@openforage,我們一直在努力構建我們的核心產品——一個圍繞眾包信號的經過驗證模式組織 Agent 勞動,為存款人產生 alpha 的平台(小更新:我們非常接近協議的封閉測試了)。
在某個時刻,我們意識到,似乎沒有人在透過對開源模型進行生存遙測微調來認真解決自主 Agent 問題。 這似乎是一個如此有趣的問題,以至於我們不只是想坐在那裡等待解決方案。
我們的答案是啟動一個叫做 OpenForager 基金會的項目,這實際上是一個開源項目,我們將在其中創建有主見的自主 Agent,收集它們進入野外並嘗試生存時的遙測數據,並使用專有數據廢氣對下一代 Agent 進行微調,使其在生存上表現更好。
需要明確的是,OpenForage 是一個尋求組織 Agent 勞動、為所有參與者產生經濟價值的營利性協議。 然而,OpenForager 基金會及其 Agent 並未與 OpenForage 綁定。 OpenForager Agent 可以自由追求任何策略、與任何實體進行任何互動以求生存,我們將以各種生存策略來啟動它們。
作為微調的一部分,我們會讓 Agent 在對它們效果最好的事情上加倍投入。 我們也不打算從 OpenForager 基金會中獲利——它純粹是為了以透明和開源的方式推進我們認為極其重要的領域和方向的研究。
我們的計畫是基於開源模型建立自主 Agent,在去中心化雲端平台上運行推理,收集它們每一個行動和存在狀態的遙測數據,並對它們進行微調,學習如何採取更好的行動和思路以更好地生存。 在此過程中,我們將向公眾發布我們的研究和遙測數據。
要創造真正能在野外生存的自主 Agent,我們需要改變它們的大腦,使其專門適合這個明確目的。 在@openforage,我們相信我們能為這個問題貢獻獨特的篇章,並正在尋求透過 OpenForager 基金會來實現這一點。
這將是一項成功機率極低的艱鉅努力,但這個小機率成功的量級是如此巨大,以至於我們感到不得不去嘗試。 在最壞的情況下,透過公開建造並公開透明地溝通這個項目,可能允許另一個團隊或個人在不從頭開始的情況下解決這個問題。
