Anthropic 資料:AI Agent 近半呼叫集中在軟體工程,這 16 個垂域仍是藍海

作者:GARry's List
編譯:深潮 TechFlow
Anthropic 最新發布了迄今為止最全面的 AI Agent 真實使用研究,核心數據是:軟體工程佔據近 50% 的 Agent 工具調用量,而醫療、法律、教育等 16 個垂直領域的 16 個垂直領域也低於垂直領域的醫療
這不是市場飽和的信號,而是 300 個垂直 AI 獨角獸的地圖——更有價值的是文章引用的一個反直覺發現:模型已經能獨立工作近 5 小時,但用戶實際上只讓它工作 42 分鐘,這個"信任赤字"本身就是下一個產品機會。
全文如下:
軟體工程佔所有 AI Agent 工具呼叫量的近 50%。 醫療、法律、金融等 16 個垂直領域幾乎未觸及,每個領域均低於 5%。 這意味著有 300 個垂直 AI 獨角獸等待被建造出來。
如果我今天要創業,我會盯著上面那張長條圖的紅色區域,直到我看見自己的未來。
Box 創辦人 Aaron Levie 表示:
這張圖很好地提醒了我們,AI Agent 領域現在有多大的機會。
水平方向當然會有大量 Agent 機會,但同樣有很多工作流程需要深厚的領域專業知識,才能真正幫助使用者自動化其所在垂直領域的獨特流程。
範本是:建構接取專有資料的 Agent 軟體,以有效銜接使用者與 Agent 協作的方式處理工作流程,同時具備深度領域專屬的情境工程能力,以及推動客戶側變更管理的能力。
目前許多領域仍存在巨大空白。
軟體工程佔據了所有 AI Agent 活動的半壁江山。 另一半則分散在 16 個垂直領域,沒有一個超過 9%。 醫療佔 1%,法律佔 0.9%,教育佔 1.8%。 這些不是飽和市場,而是幾乎還不存在的市場。
Anthropic 剛剛發布了迄今最全面的 AI Agent 真實使用研究。 核心發現是:軟體工程佔其 API 上 49.7%的 Agent 工具呼叫量。 被埋在後面的核心結論是:其他一切都是藍海。
部署滯後
有一個資料應該讓創業者興奮不已:模型的能力已經遠超使用者願意信任它的邊界。
METR 的能力評估顯示,Claude 可以解決需要人類近五小時才能完成的任務。 但在實際使用中,第 99.9 百分位的會話時長只有約 42 分鐘。 這個差距——AI 能做什麼與我們允許它做什麼之間的差距——是一個巨大的機會。
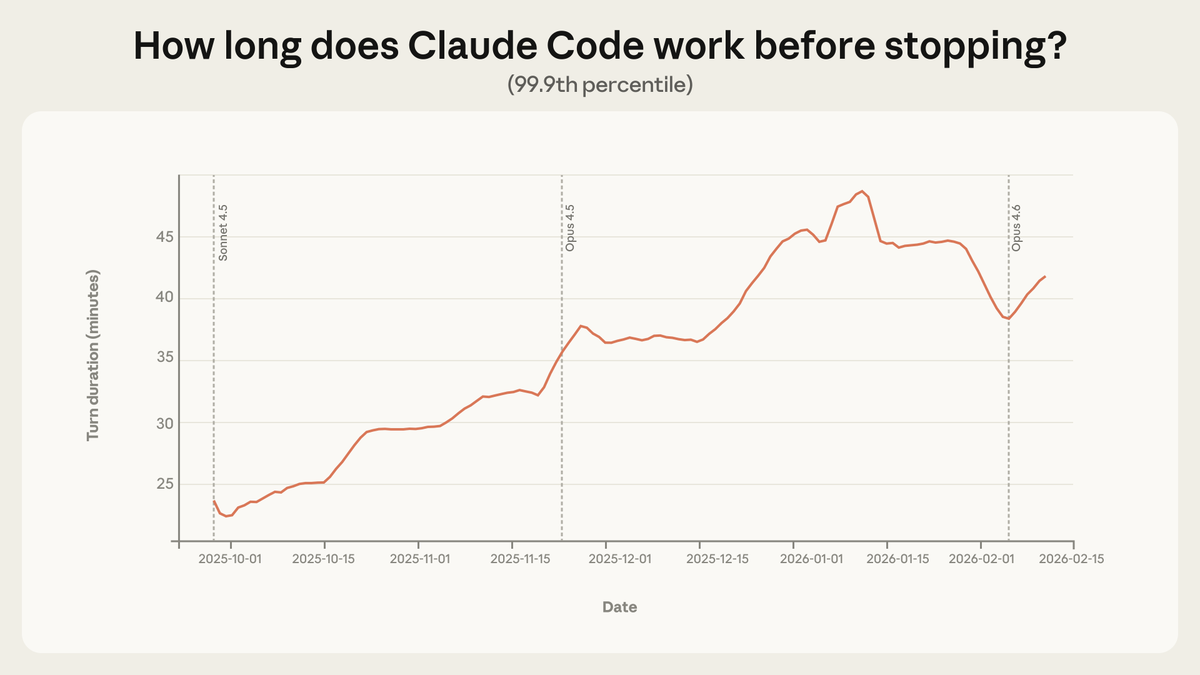
圖:Claude Code 訓練的最長時長在三個月內幾乎翻了一番。 這不僅提升了能力,也增強了信任。
來源:x.com
從 2025 年 10 月到 2026 年 1 月,第 99.9 百分位的單次會話時長幾乎翻了一倍,從不到 25 分鐘增長至超過 45 分鐘。 成長在各個模型版本間都很平穩。 這不只是模型變得更強了,而是使用者一次次地在使用中學習,逐漸延伸著對 Agent 的信任。
"從 8 月到 12 月,Claude Code 在內部用戶最具挑戰性任務上的成功率翻了一倍,與此同時,每次會話的人工幹預次數從 5.4 次減少到 3.3 次。"
能力已經在那裡,部署還沒跟上。 這不是問題,而是產品機會。
信任是如何演化的
新使用者中有 20%會自動批准 Claude Code 的操作。 到 750 次會話時,超過 40%的會話完全在自動批准模式下運行。 但有一個反直覺的發現:有經驗的使用者反而會更多地幹預,而不是更少。 新用戶會在 5%的輪次中幹預,老用戶則是 9%。
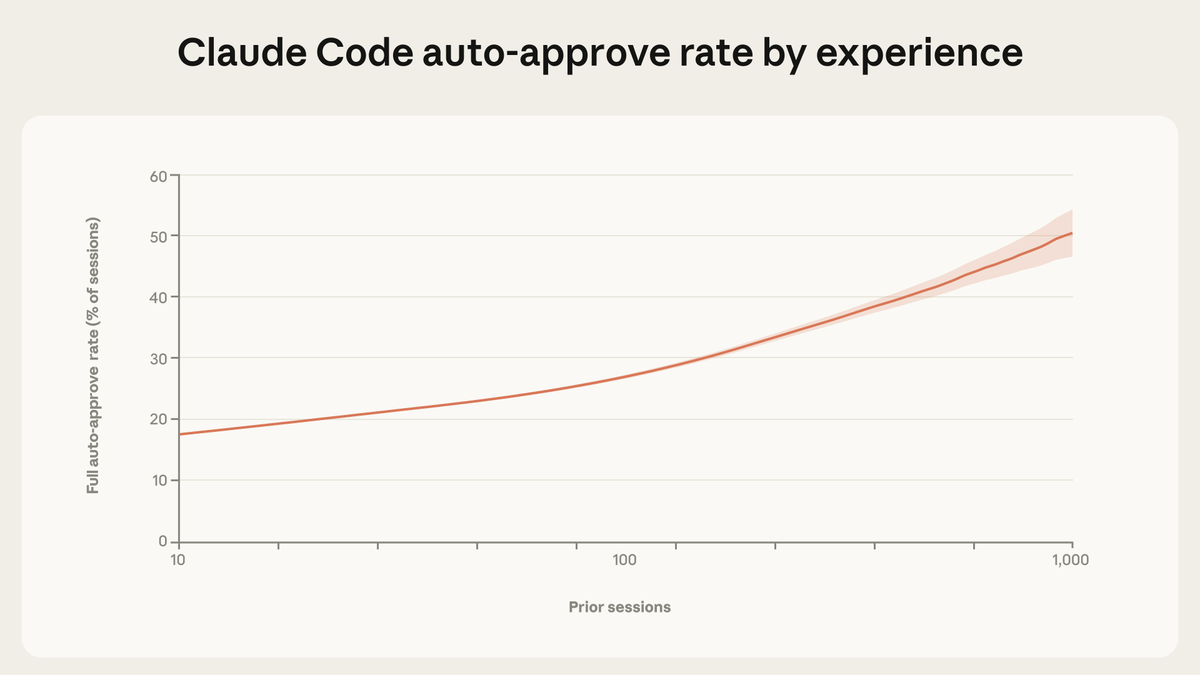
圖:信任是一種會不斷累積的技能。 新用戶會自動批准 20% 的會話。 到 750 次會話時,這一比例會超過 40%。
圖:Anthropic
來源: x.com
這並不矛盾,而是監督策略的轉變。 初學者在操作發生前逐步審批,老用戶則是先授權、在出問題時再介入——他們已經從預先審批轉向了主動監控。
以下是一個在安全層面值得關注的發現:在複雜任務上,Claude Code 主動請求澄清的頻率超過人類主動幹預頻率的兩倍。 Agent 會暫停確認,而不是一路衝到底。 這是特性,不是缺陷。
"這項研究的核心啟示是:Agent 在實踐中行使的自主權,是由模型、用戶和產品共同構建的。Claude 在不確定時會暫停提問,以此限制自身的獨立性。用戶在與模型協作的過程中建立信任,並相應地調整自己的監督策略。"
